
Préambule
Premièrement nous vous invitons à lire cet Article, si vous ne connaissez pas Cypress.
Qu’est-ce que le test End-2-end ?
Les tests end to end vérifient que tous les composants d’un système sont capables de fonctionner de manière optimale dans des situations réelles.
À savoir, on vient simuler un environnement d’utilisateur lambda, dans un contexte de navigateur.
Une différence de taille
Le test end to end, est différent du test unitaire. Le test unitaire, que la plupart des développeurs incluent à leur travail, vient vérifier l’essence même du code, par exemple une fonction ou un algorithme, sur la logique.
Quant à lui, le test end to end, est destiné à simuler un comportement utilisateur sur un scénario complet, sur tous les éléments visuels sur lesquels l’utilisateur peut interagir.
Durant tout ce parcours, nous allons donc nous focaliser sur les tests end to end.
En ce qui nous concerne, nous parlerons de tests de régression automatisés en CI/CD.
Rentrons un peu plus dans le détail.
Mais qu’est-ce que cela signifie?
Cas pratique :
Je suis un utilisateur qui se connecte à un site d’e-commerce, je cherche un article, je l’achète, je reçois le mail de validation de commande puis je me déconnecte.
Voici quelques exemples :
- Tester des éléments visuels du site.
- Tester la navigation et la disponibilité de toutes les pages.
- Tester les règles d’affichages.
- Saisir de mauvaises valeurs pour vérifier la bonne gestion des erreurs.
- Faire d’éventuelles requêtes vers des API…
Il ne faut bien sûr pas négliger les tests unitaires pour autant. Ce sont deux choses bien complémentaires.
Dans cet article, nous allons aborder les différentes approches pour mettre en place nos tests automatisés Cypress, en intégration continue, et plus précisément en utilisant Gitlab Ci pour l’exemple.
Ces tests de non-régression, vont s’exécuter automatiquement, selon certains choix de paramètres, à chaque fois qu’un déploiement sera initié.
Notre démarche est possible avec les différentes solutions les plus utilisées actuellement et pour ne citer que les plus connues :
- Gitlab
- Github Actions
- CircleCI
- BitBucket
- Jenkins
- AWS Codebuild
- Azure Devops
Quelques clés pour mieux appréhender cet article
Tests de non-régression ?
Un test de régression (ou de non-régression) est un ensemble de tests effectués sur un programme, après une modification, pour s’assurer que des défauts n’ont pas été introduits ou découverts dans des parties non modifiées du logiciel. Ces tests sont effectués quand le logiciel ou son environnement est modifié.
Ce sont des tests qui vont permettre de détecter tout effet de bord causé par n’importe quelle modification ou nouvelle fonctionnalité.
Quels sont les avantages ?
- Ces tests automatisés sont intégrables facilement dans une chaîne d’intégration continue, qui va permettre de systématiser leur lancement à chaque envoi de code et ainsi de détecter d’éventuels problèmes fonctionnels avant toute nouvelle livraison.
- Cela va également permettre de gagner en temps de travail pour une ou plusieurs autres personnes, étant donné que les tests se lanceront seuls.
Exemple :
Nous avons récemment mis en place ce type d’environnement pour un client.
Temps de développement des tests automatisés : 10 jours.
L’équipe en charge du projet, passait près de 1 h 30, à raison de 2 personnes, à chaque nouvelle livraison, à effectuer tous ces tests de non-régression.
Les tests ont été développés et mis en place en intégration continue.
Résultats : Leur temps n’est plus imputé par ces tâches récurrentes, ils sont moins débordés et peuvent utiliser ce temps pour des choses autant importantes, voire plus.
Pilule bleue ou pilule rouge ?
La première étape va concerner le choix de plusieurs éléments.
Tout d’abord, selon les contraintes du client, de son infrastructure et de son équipe, il va falloir poser les bases et choisir un environnement.
Environnement
Dans l’idéal, afin de s’isoler de toute interaction extérieure, avoir un environnement et une BDD dédiés, c’est le TOP !
Donc dans le cadre où c’est possible, ne pas hésiter à faire mettre en place cet environnement avec :
- Credentials
- Clés « TEST » de captcha
- Clés API
- Sandbox
- Accès dashboard divers : Mangopay…
- Ou tout autre contrainte liée à la solution du projet.
Vous l’aurez compris, je ne vais pas faire une liste exhaustive, cela serait impossible…
Et quand l’environnement dédié est impossible pour diverses raisons, il faudra faire avec l’environnement de recette standard.
Il faudra vous adapter aux problématiques inhérentes au projet qui en découle, pas de conseils particuliers ici, car c’est du pur cas par cas.
Les Variables de CI
Pour continuer dans une démarche d’automatisation complète, l’utilisation de variable CI/CD est indispensable pour garantir la flexibilité et la sécurité du projet.
Les règles sont les mêmes que pour un environnement classique :
- Pas de secret dans les scripts de CI/CD.
- Variabilisation de tout ce qui peut-être variabilisé (verbosité des logs, url…).

Dans l’exemple ci-dessus, nous venons simplement de fournir à notre script de lancement Cypress :
- Une URL de base sur laquelle il va venir faire ses requêtes HTTP.
- Une URL de base pour réaliser des calls API.
Plusieurs possibilités :
- Soit on inclut directement les variables dans le fichier de configuration Cypress (cypress.config.js).
- Soit on se créer un objet à l’intérieur du fichier de configuration où l’on peut venir encapsuler toutes nos variables, que j’ai appelé ici en l’occurrence : env
Les images docker
Pas vraiment de soucis pour les images, car Cypress a mis en place et maintient un panel d’images officielles disponible via :
Le reporting des tests
Quand tout se passe bien c’est cool. Mais quand des tests sont KO, il est indispensable de savoir pourquoi.
Cypress permet de retracer chaque échec de test, d’avoir un rapport de métriques et tout autre données susceptible de nous faciliter la tâche pour retrouver le(s) bug(s).
Pour ma part, j’utilise Mochawesome Reporter, il est très complet et permet de générer des rapports de tests formatés en HTML qui aident grandement à la lisibilité, avec énormément d’informations complémentaires.
Nous l’évoquons maintenant, car il sera inclus dans nos artefacts de pipeline.
Le pipeline
Nous arrivons au moment où nous allons mettre en place la CI.
On part du principe que votre dossier cypress est à la racine de votre projet dans votre repository.
Désormais, tout ce qu’il va nous rester à faire, c’est de configurer ou de créer son fichier .gitlab-ci.yml.
YAML?
Pour apprendre la syntaxe du langage, je vous invite à suivre ce lien.
Rien de compliqué, mais il y a quelques mots-clés à connaître.
Les différentes étapes de notre yaml
Stages
En règle générale (hors cas spécifiques), on va retrouver :
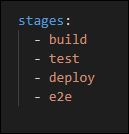
- build, test, deploy : ces trois-là, nous sont fournis par l’équipe de développeurs ou le lead et généralement on y touche pas du tout, ce sont les phases avant les tests end-to-end. (TEST = tests unitaires)
- e2e : La partie qui nous intéresse !
Dans notre cas, on va simplement venir ajouter notre stage aux autres à la fin.
Le job
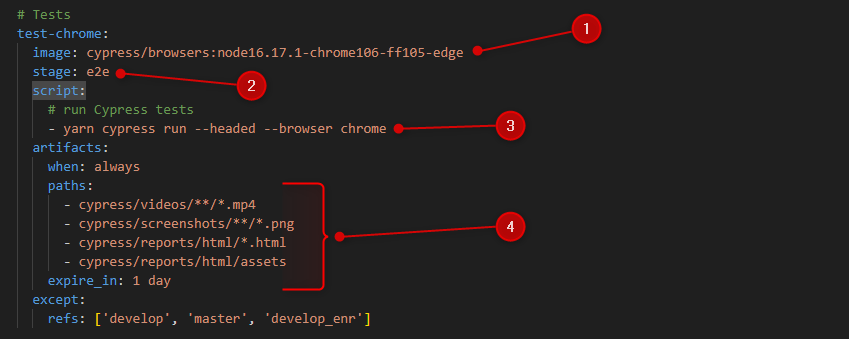
Voici comment va se découper notre job :
- L’image que nous avons choisie préalablement.
- Le stage dont le libellé est « e2e ».
- Le script avec la ligne de commande de lancement dont nous parlons plus en détails dans la partie variables de CI, précédemment évoquée (Nous n’allons pas entrer dans les détails de toutes les possibilités de la ligne de commande, je pars du principe que vous les connaissez déjà à ce stade).
- Dans cette partie, nous allons déclarer les artefacts, tout ce que nous voulons garder après chaque exécution de pipeline : les vidéos, les captures d’écrans ainsi que les rapports de tests en HTML (le dossier assets est présent pour mettre en forme le CSS de nos rapports de tests tout beaux).
expire_insert à préciser combien de temps, nous voulons garder ces artefacts. Nous considérons que les garder une journée est suffisant. Après une journée, les artefacts seront supprimés et libèrent ainsi la ressource sur le disque. Il suffit de relancer le job pour les régénérer.whenpour savoir quels événements vont déclencher la création de ces artefacts, ça peut êtreon_success,on_failureetalways.- Quant à la partie
except, c’est simplement pour stipuler quand nous NE voulons PAS, que le jobtest-chromesoit lancé.
Et voilà !
Votre YAML est prêt avec une configuration simple. Il se peut que vous deviez vous adapter sur certains projets et écrire votre .yml de manière différente, mais vous avez les bases nécessaires pour vous adapter à toute situation. (en principe)
Pour aller plus loin et configurer la montagne de paramètres qu’il est possible de configurer, je vous laisse explorer.
Vous allez pouvoir exécuter vos tests seulement sur certaines actions, à certains moments sur certains environnements, les possibilités sont multiples…
La seule limite est votre imagination. La documentation officielle de Cypress vous aidera à développer vos tests, même les plus complexes.
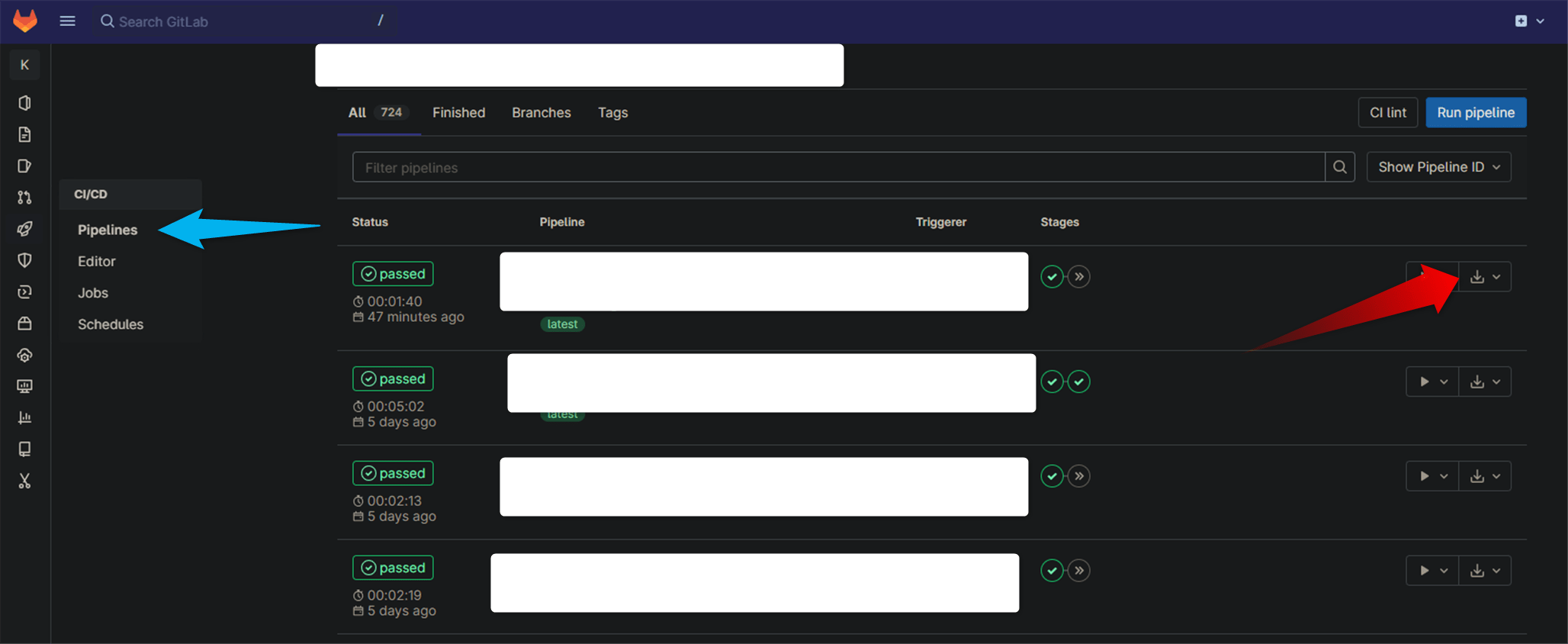
Dès que votre pipeline aura fini de tourner, vous pourrez télécharger vos artefacts dans cette section (flèche bleue) ci-dessous, en cliquant sur le bouton (flèche rouge).
Pour aller plus loin…
Si jamais le besoin s’en fait ressentir ou que cela vous intéresse, sachez qu’il est possible de paralléliser plusieurs jobs de tests sur votre pipeline.
Pour que cela soit plus parlant, voici quelques exemples :
- Job#1 : Tests end-2-end du projet, webkit 2532 x 1170 pixels.
- Job#2 : Tests end-2-end du projet, chrome 2732 x 2048 pixels.
- Job#3 : Tests end-2-end du projet, firefox 1920 x 1080 pixels.
Qui est Benjamin Vasseur ?
Initialement issu d’une formation de développeur JavaScript, formé à la QA, et principalement à l’automatisation. Je suis également certifié ISTQB.


